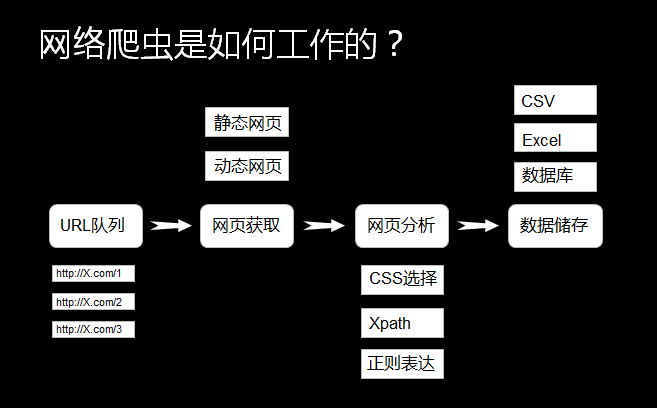
实例:爬前程无忧招聘信息
# 职位:Linux
# 搜索1页:
#https://search.51job.com/list/170300,000000,0000,00,9,99,Linux,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=
#https://search.51job.com/list/170300,000000,0000,00,9,99,Linux,2,1.html?lang=c
# 搜索2页:
import re
import requests
key="Linux"
data={
您暂时无权查看此隐藏内容!
"curr_page":"1",
}
hd={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36"}
response=requests.get("http://search.51job.com/jobsearch/search_result.php",params=data,headers=hd)
# 转码通用方式
data=bytes(response.text,response.encoding).decode("gbk","ignore")
pat_page="共(.*?)条职位"
allline=re.compile(pat_page,re.S).findall(data)[0]
allpage=int(allline)//50-1
print(str(allpage))
for i in range(0,allpage):
print("---正在爬"+str(i+1)+"页---")
getdata={"fromJs":'1',
"jobarea":"0200000",
"keyword":key,
"keywordtype":"2",
"curr_page":str(i+1),
}
response=requests.get("http://search.51job.com/jobsearch/search_result.php",params=getdata,headers=hd)
thisdata=bytes(response.text,response.encoding).decode("gbk","ignore")
job_url_pat='<em class="check" name="delivery_em" onclick="checkboxClick.*?href="https://jobs.51job.com/(.*?).html'
job_url_all=re.compile(job_url_pat,re.S).findall(thisdata)[1:]
for job_url in job_url_all:
thisurl="http://jobs.51job.com/"+job_url+".html"
response=requests.get(thisurl)
thisdata=bytes(response.text,response.encoding).decode("gbk","ignore")
pat_title='<h1 title="(.*?)"'
#pat_company='<div class="tHeader tHjob">.*?title="(.*?)"'
pat_company='<div class="tHeader tHjob">.*?class="catn">(.*?)<em class="icon_b i_link">'
pat_money='<div class="tHeader tHjob">.*?<strong>(.*?)</strong>'
pat_msg='<div class="bmsg job_msg inbox">(.*?)<div class="mt10">'
title=re.compile(pat_title,re.S).findall(thisdata)[0]
company=re.compile(pat_company,re.S).findall(thisdata)[0]
money=re.compile(pat_money,re.S).findall(thisdata)
msg=re.compile(pat_msg,re.S).findall(thisdata)[0]
print("----------")
print("标题:"+str(title))
print("公司:"+str(company))
print("薪资:"+str(money))
print("介绍:"+str(msg))
内容查看价格9.9元立即支付
注意:本站少数资源收集于网络,如涉及版权等问题请及时与站长联系,我们会在第一时间内与您协商解决。如非特殊说明,本站所有资源解压密码均为:zhangqiongjie.com。
作者:1923002089




评论前必须登录!
注册