Urllib模块是一个可以用于编写爬虫的非常常用的模块,在安装好Python后自带安装了Urllib模块,可以直接使用。
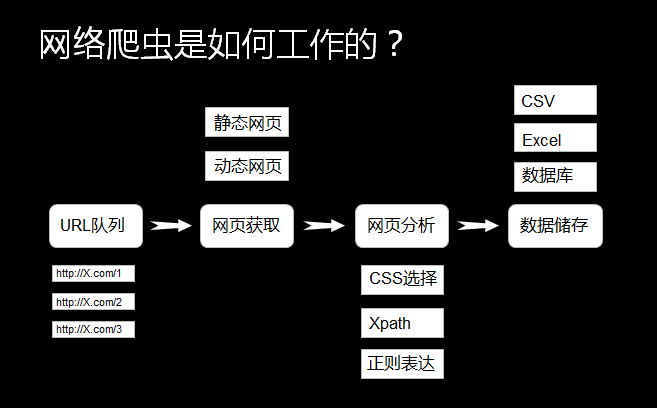
实例(爬虫糗事百科数据):
import urllib
import urllib.request
import re
import random
def getdata(url):
# 请求数据
data=urllib.request.urlopen(str(url)).read().decode("utf-8","ignore")
return data
uapools=[
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36 OPR/66.0.3515.44"
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36"
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"
]
def UA():
opener=urllib.request.build_opener()
thisua=random.choice(uapools)
ua=("User-Agent",thisua)
opener.addheaders=[ua]
urllib.request.install_opener(opener)
#print("当前使用UA:"+str(thisua))
url="https://www.qiushibaike.com/hot/page/1/"
# 每爬3次换一次UA
for i in range(0,10):
if(i%3==0):
UA()
# 异常处理
try:
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
# 正则表达式
pat='<div class="content">.*?<span>(.*?)</span>.*?</div>'
rst=re.compile(pat,re.S).findall(data)
print(rst)
print(len(rst))
for j in range(0,len(rst)):
print(rst[j])
print("------------------")
except Exception as err:
pass
#下载网页到本机
#urllib.request.urlretrieve("http://zhangqiongjie.com",filename="C:\\learning\\Python\\spider\\urllib\\zqj.html")




评论前必须登录!
注册