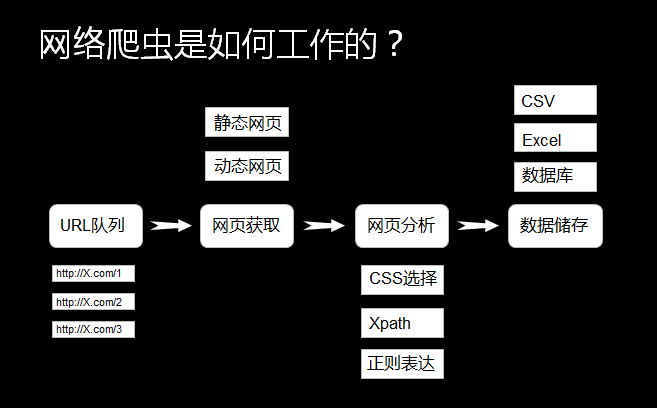
除了使用Urllib模块编写爬虫外,还有其他很多模块可供选择,如Request模块和Scrapy框架都是常用的爬虫手段,根据自己的爱好自由选择。爬虫的难点不在于技术手段本身,而在于网页分析和反爬攻克,如下是Request模块的基础使用方法。
# 请求方式: get 、post 、 put ...
# request.get()
# request.post()
# request.put()
# 常用参数:params(get请求参数)、headers、proxies、cookies、data(post请求参数)
'''
text: 相应数据
content:响应数据(二进制bety类型)
encoding:当前网页编码
cookies: 响应cookie
url:当前请求的url
status_code: 当前网页的请求状态码
'''
import requests
import re
import random
# 一、Get请求方式
url="http://www.zhangqiongjie.com"
# 伪装浏览器
uapools=[
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36 OPR/66.0.3515.44"
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36"
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"
]
hd={"User-Agent":random.choice(uapools)}
# 添加代理IP
px={"http":"http://127.0.0.1:8888"}
# 格式
#data=requests.get(url,headers=hd,proxies=px,cookies={""})
data=requests.get(url,headers=hd)
pat='<meta name="keywords".*?content=(.*?)>'
kw=re.compile(pat,re.S).findall(data.text)
#print("kw:"+str(kw))
para={"wd":"阿里文学",}
rst=requests.get("http://www.baidu.com/s",params=para,proxies=px)
# 1.获取返回网页源代码、类型
rst.text
type(rst.text)
# 2.获取返回网页二进制源代码、类型
rst.content
type(rst.content)
# 3.获取返回网页编码、类型
rst.encoding
type(rst.encoding)
# 4.获取返回网页cookies值
rst.cookies
type(rst.cookies)
# 5.获取当前url
rst.url
# 6.获取当前状态码
rst.status_code
# 将cookies转为字典形式
requests.utils.dict_from_cookiejar(rst.cookies)
# 二、Post请求
#postdata={"name":"账号名称","pass":"账号密码"}
#requests.post(url,data=postdata)
# 案例(爬云栖社区)
key="Linux"
mainurl="https://yq.aliyun.com/search/articles/"
data=requests.get(mainurl,params={"q":key}).text
pat1='<div class="_search-info">找到(.*?)条关于'
pageNum=re.compile(pat1,re.S).findall(data)[0]
Num=int(pageNum)//15-1
您暂时无权查看此隐藏内容!
# print(pageContent.text)
for j in range(0,len(articleLinks)-1):
midurl="https://yq.aliyun.com"+articleLinks[j]
print("midurl: "+midurl)
articleContent=requests.get(midurl).text
title=re.compile('<p class="hiddenTitle">(.*?)</p>',re.S).findall(articleContent)
article=re.compile('<div class="content-detail unsafe markdown-body">(.*?)</div>',re.S).findall(articleContent)
fh=open("C:\\Philips\\2Normal\\personal\\learning\\Python\\spider\\urllib\\"+str(j)+"_"+".html","w",encoding="utf-8")
#fh.write(title+"<br /><br />"+article)
fh.write(str(title)+"<br /><br />"+str(article))
fh.close()
内容查看价格9.9元立即支付
注意:本站少数资源收集于网络,如涉及版权等问题请及时与站长联系,我们会在第一时间内与您协商解决。如非特殊说明,本站所有资源解压密码均为:zhangqiongjie.com。
作者:1923002089




评论前必须登录!
注册