一、部署准备和完成目标
1.准备
1.服务器4台,本示例的操作系统为CentOS Linux release 7.8.2003 (Core),其中一台为主节点master01,其余三台为从节点,分别为node01,node02,node03。
192.168.239.130 master01
192.168.239.131 node01
192.168.239.132 node02
192.168.239.133 node03
2.安装ansible自动化工具
为了后面操作步骤简单,在master01节点安装ansible工具后可直接在从节点上进行安装和配置操作,不需要分别到各个从节点执行同样的命令。ansible的安装部署和使用参考:Ansible之roles角色的使用方法总结的第五条“五、Roles使用实例”
提示:如果不熟练ansible工具,不安装也可以,后面通过ansible执行的命令或操作分别在每个节点执行操作即可。
2.目标
配置一个主节点和三个从节点的Hadoop-YARN集群。集群中所用的各个节点必须有一个唯一的主机名和IP地址,并能够基于主机互相通信。如果没有配置合用的DNS服务,也可以通过/etc/hosts文件进行主机解析,
二、安装部署
1.配置master和node节点运行环境
配置master节点,需要修改core-site.xml和yarn-site.xml配置文件中的“localhost”主机名称或地址为master节点的主机名称或地址,并在slaves文件中指明各从节点名称或地址即可。
1.配置hosts文件
192.168.239.130 master01.zhang.com master01 192.168.239.131 node01.zhang.com node01 192.168.239.132 node02.zhang.com node02 192.168.239.133 node03.zhang.com node03
复制/etc/hosts文件到各个从节点:
[root@master01 ~]# for i in 1 2 3; do scp /etc/hosts root@node0${i}:/etc/hosts; done
2.编辑环境配置文件
[root@master01 ~]# vim /etc/profile.d/hadoop.sh
export HADOOP_PREFIX=/bdapps/hadoop
export PATH=$PATH:${HADOOP_PREFIX}/bin:${HADOOP_PREFIX}/sbin
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_YARN_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}
复制到其他节点
[root@master01 ~]# for i in 1 2 3; do scp /etc/profile.d/hadoop.sh root@node0${i}:/etc/profile.d/; done
3.配置java环境
[root@master01 ~]# cat /etc/profile.d/java.sh export JAVA_HOME=/usr
复制/etc/profile.d/java.sh到各个从节点
[root@master01 ~]# for i in 1 2 3; do scp /etc/profile.d/java.sh root@node0${i}:/etc/profile.d/java.sh; done
4.下载jdk程序包
您暂时无权查看此隐藏内容!
3.免密登录验证结果
[hadoop@master01 .ssh]$ for i in 1 2 3; do ssh node0${i} 'date'; done;
Thu Aug 6 10:35:09 CST 2020
Thu Aug 6 10:35:30 CST 2020
Thu Aug 6 10:35:50 CST 2020
4.下载Hadoop并配置其目录
1.在各个节点上创建相关目录:
[root@master01 ansible]# ansible allCentOS -m shell -a " mkdir -pv /bdapps /data/hadoop/hdfs/{nn,snn,dn}"
2.给/data/hadoop/hdfs目录授权
[root@master01 ansible]# ansible allCentOS -m shell -a "chown -R hadoop:hadoop /data/hadoop/hdfs"
3.下载hadoop
官网:https://hadoop.apache.org/release/2.10.0.html,wget下载:
[root@centos01 ~]# wget https://archive.apache.org/dist/hadoop/common/hadoop-2.10.0/hadoop-2.10.0.tar.gz [root@master01 ~]# tar zxf hadoop-2.10.0.tar.gz -C /bdapps/
先将hadoop软件包下载到master01节点,然后复制hadoop安装包到其他节点
[root@master01 ~]# for i in 1 2 3; do scp hadoop-2.10.0.tar.gz root@node0${i}:/bdapps/; done
解压
[root@master01 ~]# ansible allCentOS -m shell -a "tar xf /bdapps/hadoop-2.10.0.tar.gz -C /bdapps/"
4.创建软连接:
[root@master01 ~]# ansible allCentOS -m shell -a "cd /bdapps/ && ln -sv hadoop-2.10.0 hadoop"
5.创建日志文件,并授权文件权限
[root@master01 ~]# ansible allCentOS -m shell -a "mkdir /bdapps/hadoop/logs && chmod g+w /bdapps/hadoop/logs && chown -R hadoop:hadoop /bdapps/hadoop/*"
5.配置Hadoop配置文件
1.core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master01:8020</value>
<final>true</final>
</property>
</configuration>
2.yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>master01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master01:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
</configuration>
3.hdfs-site.xml
修改dfs.replication属性的值为所需要的冗余的数值,例如:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop/hdfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop/hdfs/dn</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>file:///data/hadoop/hdfs/snn</value>
</property>
<property>
<name>fs.checkpoint.edits.dir</name>
<value>file:///data/hadoop/hdfs/snn</value>
</property>
</configuration>
4.mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.slave
node01 node02 node03
通过hadoop用户身份,复制以上配置文件到其他各个节点:
[root@master01 ~]# su - hadoop
Last login: Thu Aug 6 10:22:58 CST 2020 on pts/0
[hadoop@master01 ~]$ for i in 1 2 3; do scp /bdapps/hadoop/etc/hadoop/* node0${i}:/bdapps/hadoop/etc/hadoop/; done
6.格式化HDFS
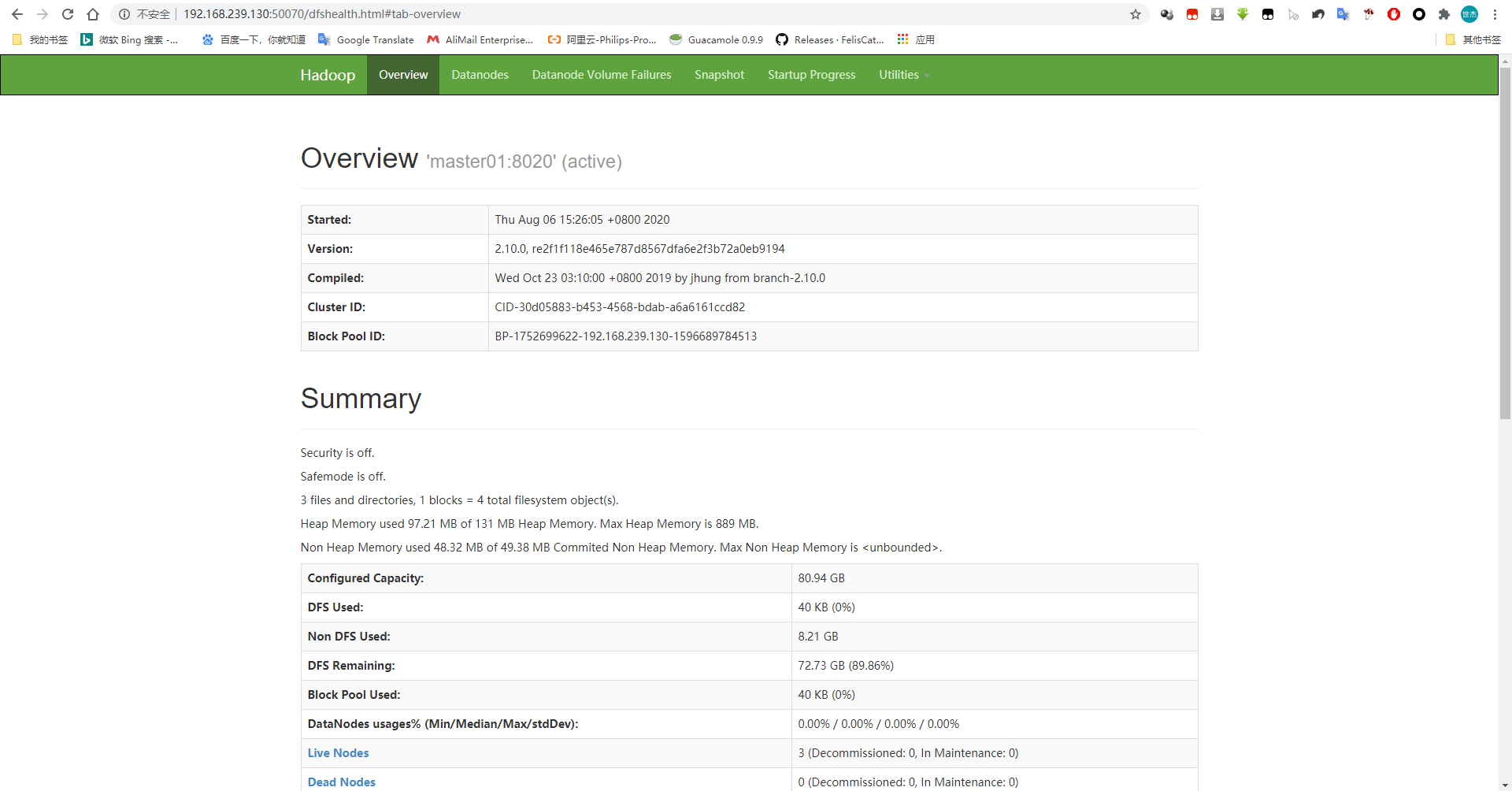
与伪分布式模式相同,在HDFS集群的NN启动之前需要先初始化其用于存储数据的目录。如果hdfs-site.xml中dfs.namenode.name.dir属性指定的目录不存在,格式化命令会自动创建之;如果事前存在,请确保其权限正确,此时格式操作会清除其内部的所有数据并重新建立一个新的文件系统,格式化:
[root@master01 ~]# su - hadoop Last login: Thu Aug 6 12:36:01 CST 2020 on pts/1 [hadoop@master01 ~]$ hdfs namenode -format 20/08/06 12:56:22 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = master01.zhang.com/192.168.239.130 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.10.0 ...... 20/08/06 12:56:24 INFO common.Storage: Storage directory /data/hadoop/hdfs/nn has been successfully formatted. ......
若格式化命令执行后的显示结果有显示如下内容,表示格式化成功:
20/08/06 12:56:24 INFO common.Storage: Storage directory /data/hadoop/hdfs/nn has been successfully formatted.
三、启动Hadoop
1.启动HDFS服务
可以分别在每个节点启动;也可以在master节点使用系统默认提供的脚本start-dfs.sh和stop-dfs.sh启动和停止整个集群,以及使用start-yarn.sh和stop-yarn.sh来启动和停止整个集群。
[hadoop@master01 ~]$ start-dfs.sh
查看各个节点进程状态:
[root@master01 ansible]# ansible allCentOS -m shell -a "su - hadoop -c jps" [WARNING]: Consider using 'become', 'become_method', and 'become_user' rather than running su 192.168.239.131 | CHANGED | rc=0 >> 3968 Jps 3579 DataNode 192.168.239.133 | CHANGED | rc=0 >> 4101 Jps 3755 DataNode 192.168.239.132 | CHANGED | rc=0 >> 3298 DataNode 3641 Jps 192.168.239.130 | CHANGED | rc=0 >> 5991 SecondaryNameNode 5786 NameNode 6637 Jps
2.启动Yarn服务
[hadoop@master01 logs]$ start-yarn.sh
查看各个节点进程状态
[root@master01 ansible]# ansible allCentOS -m shell -a "su - hadoop -c jps" [WARNING]: Consider using 'become', 'become_method', and 'become_user' rather than running su 192.168.239.131 | CHANGED | rc=0 >> 4277 NodeManager 4439 Jps 3579 DataNode 192.168.239.132 | CHANGED | rc=0 >> 3952 NodeManager 3298 DataNode 4115 Jps 192.168.239.130 | CHANGED | rc=0 >> 7777 ResourceManager 5991 SecondaryNameNode 8201 Jps 5786 NameNode 192.168.239.133 | CHANGED | rc=0 >> 3755 DataNode 4412 NodeManager 4575 Jps
四、Hadoop简单使用
1.在hadoop中创建目录
[hadoop@master01 logs]$ hdfs dfs -mkdir /test
2.上传文件
[hadoop@master01 logs]$ hdfs dfs -put /etc/fstab /test/
3.查看文件内容
[hadoop@master01 logs]$ hdfs dfs -cat /test/fstab # # /etc/fstab # Created by anaconda on Sun Jul 12 17:56:16 2020 # # Accessible filesystems, by reference, are maintained under '/dev/disk' # See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info # /dev/mapper/centos_centos01-root / xfs defaults 0 0 UUID=f633a85c-6115-4073-959b-17b808f93d4e /boot xfs defaults 0 0 /dev/mapper/centos_centos01-swap swap swap defaults 0 0
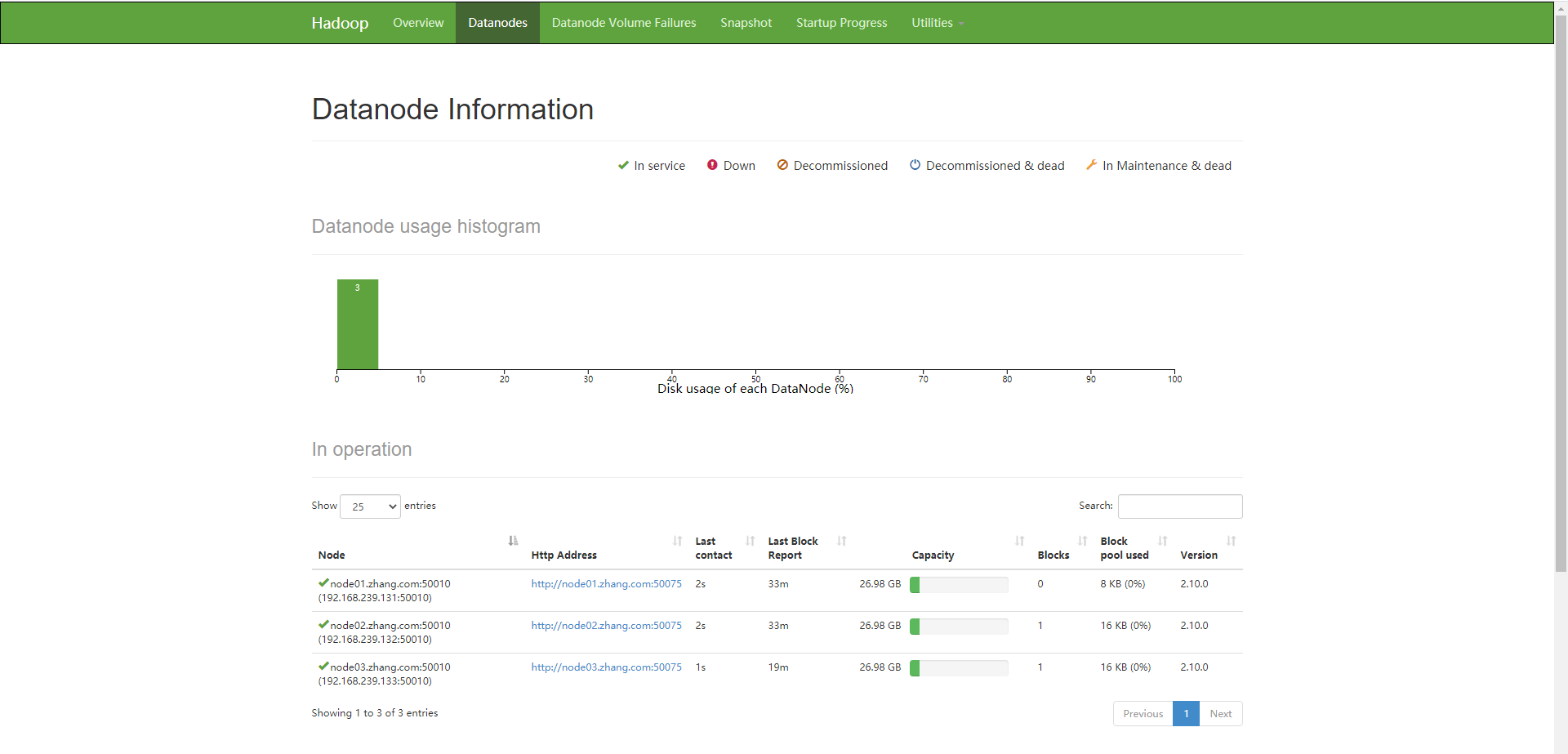
4.查看各个节点,如下表示已生成数据
[root@master01 ansible]# ansible allCentOS -m shell -a "ls /data/hadoop/hdfs/dn/" 192.168.239.133 | CHANGED | rc=0 >> current in_use.lock 192.168.239.131 | CHANGED | rc=0 >> current in_use.lock 192.168.239.132 | CHANGED | rc=0 >> current in_use.lock 192.168.239.130 | CHANGED | rc=0 >>
5.hadoop统计文件中每个单词出现的次数
[hadoop@master01 logs]$ yarn jar /bdapps/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar wordcount /test/fstab /test/wordcount
五、YARN集群管理命令
yarn命令有许多子命令,大体可分为用户命令和管理命令两类,直接运行yarn命令,可显示器简单使用语法及各子命令的简单使用。
[hadoop@master01 logs]$ yarn
Usage: yarn [--config confdir] [COMMAND | CLASSNAME]
CLASSNAME run the class named CLASSNAME
or
where COMMAND is one of:
resourcemanager run the ResourceManager
Use -format-state-store for deleting the RMStateStore.
Use -remove-application-from-state-store <appId> for
removing application from RMStateStore.
nodemanager run a nodemanager on each slave
timelinereader run the timeline reader server
timelineserver run the timeline server
rmadmin admin tools
router run the Router daemon
sharedcachemanager run the SharedCacheManager daemon
scmadmin SharedCacheManager admin tools
version print the version
jar <jar> run a jar file
application prints application(s)
report/kill application
applicationattempt prints applicationattempt(s)
report
container prints container(s) report
node prints node report(s)
queue prints queue information
logs dump container logs
schedulerconf updates scheduler configuration
classpath prints the class path needed to
get the Hadoop jar and the
required libraries
cluster prints cluster information
daemonlog get/set the log level for each
daemon
top run cluster usage tool
Most commands print help when invoked w/o parameters.
常用命令:
- yarn application <options>
- yarn node <options>
- yarn logs <options>
- yarn classpath <options>
- yarn version <options>
- yarn rmadmin <options>
- yarn daemonlog <options>
[hadoop@master01 logs]$ yarn application -list
[hadoop@master01 logs]$ yarn application -list -appStates=all
[hadoop@master01 logs]$ yarn application -status Application-Id
[hadoop@master01 logs]$ yarn node -list
20/08/06 16:49:23 INFO client.RMProxy: Connecting to ResourceManager at master01/192.168.239.130:8032
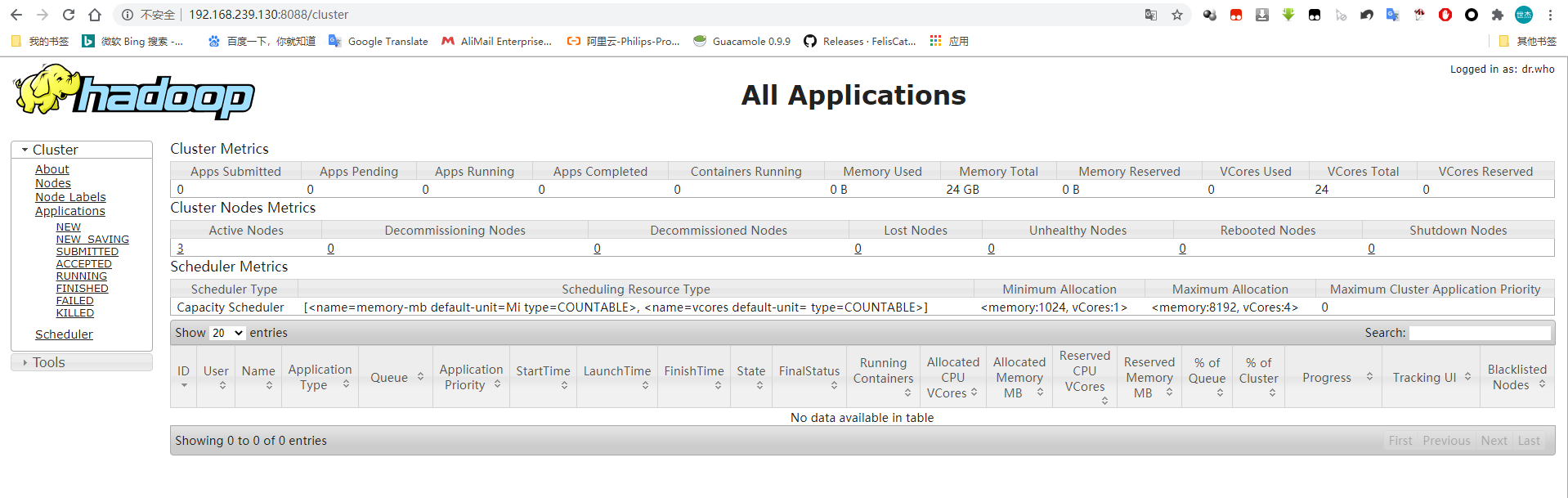
Total Nodes:3
Node-Id Node-State Node-Http-Address Number-of-Running-Containers
node01.zhang.com:35395 RUNNING node01.zhang.com:8042 0
node03.zhang.com:33345 RUNNING node03.zhang.com:8042 0
node02.zhang.com:42587 RUNNING node02.zhang.com:8042 0
六、网页展示
HDFS和YARN ResourceManager各自提供了一个Web接口,通过这些接口可检查HDFS集群即YARN集群的相关状态信息,它们的访问接口如下,实际使用中,需要将NameNodeHost和ResourceManagerHost分别改为其相应的主机地址:
- HDFS-NameNode: http://<NameNodeHost>:50070/
- YARN-ResourceManager: http://<ResourceManagerHost>:8088/
注意:yarn-site.xml文件中yarn.resourcemanager.webapp.address属性的值如果定义为“”“localhost:8088”,则WebUI仅监听于127.0.0.1地址上的8088端口。
伪分布式hadoop模型的安装部署参考琼杰笔记文档:


评论前必须登录!
注册