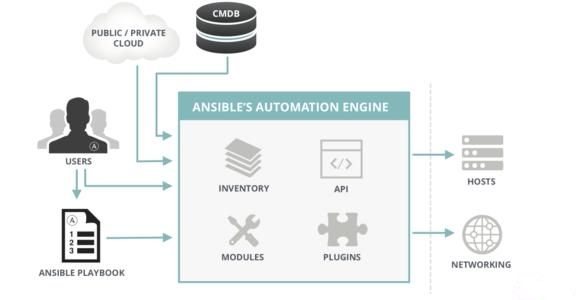
参考琼杰笔记文档:
1.1 ansible facts
facts组件是用来收集被管理节点信息的,使用setup模块可以获取这些信息。
ansible-doc -s setup
– name: Gathers facts about remote hosts
以下是某次收集的信息示例。由于收集的信息项非常多,所以截取了部分内容项。
ansible 192.168.100.64 -m setup
192.168.100.64 | SUCCESS => {
"ansible_facts": {
"ansible_all_ipv4_addresses": [
"192.168.100.64"
],
"ansible_all_ipv6_addresses": [
"fe80::20c:29ff:fe03:a452"
],
"ansible_apparmor": {
"status": "disabled"
},
"ansible_architecture": "x86_64",
"ansible_bios_date": "07/02/2015",
"ansible_bios_version": "6.00",
"ansible_cmdline": {
"BOOT_IMAGE": "/vmlinuz-3.10.0-327.el7.x86_64",
"LANG": "en_US.UTF-8",
"biosdevname": "0",
"crashkernel": "auto",
"net.ifnames": "0",
"quiet": true,
"ro": true,
"root": "UUID=b2a70faf-aea4-4d8e-8be8-c7109ac9c8b8"
},
........................................
"ansible_default_ipv6": {},
"ansible_devices": {
"sda": {
"holders": [],
"host": "SCSI storage controller: LSI Logic / Symbios Logic 53c1030 PCI-X Fusion-MPT Dual Ultra320 SCSI (rev 01)",
"model": "VMware Virtual S",
"partitions": {
"sda1": {
"holders": [],
"sectors": "512000",
"sectorsize": 512,
"size": "250.00 MB",
"start": "2048",
"uuid": "367d6a77-033b-4037-bbcb-416705ead095"
},
"sda2": {
"holders": [],
"sectors": "37332992",
"sectorsize": 512,
"size": "17.80 GB",
"start": "514048",
"uuid": "b2a70faf-aea4-4d8e-8be8-c7109ac9c8b8"
},
................................
"ansible_user_dir": "/root",
"ansible_user_gecos": "root",
"ansible_user_gid": 0,
"ansible_user_id": "root",
"ansible_user_shell": "/bin/bash",
"ansible_user_uid": 0,
"ansible_userspace_architecture": "x86_64",
"ansible_userspace_bits": "64",
"ansible_virtualization_role": "guest",
"ansible_virtualization_type": "VMware",
"module_setup": true
},
"changed": false
}
使用filter可以筛选指定的facts信息。例如:
ansible 192.168.100.64 -m setup -a "filter=changed"
192.168.100.64 | SUCCESS => {
"ansible_facts": {},
"changed": false
}
ansible localhost -m setup -a "filter=*ipv4"
localhost | SUCCESS => {
"ansible_facts": {
"ansible_default_ipv4": {
"address": "192.168.100.62",
"alias": "eth0",
"broadcast": "192.168.100.255",
"gateway": "192.168.100.2",
"interface": "eth0",
"macaddress": "00:0c:29:d9:0b:71",
"mtu": 1500,
"netmask": "255.255.255.0",
"network": "192.168.100.0",
"type": "ether"
}
},
"changed": false
}
facts收集的信息是json格式的,其内任一项都可以当作变量被直接引用(如在playbook、jinja2模板中)引用。见下文。
1.2 变量引用json数据的方式
在ansible中,任何一个模块都会返回json格式的数据,即使是错误信息都是json格式的。
在ansible中,json格式的数据,其内每一项都可以通过变量来引用它。当然,引用的前提是先将其注册为变量。
例如,下面的playbook是将shell模块中echo命令的结果注册为变量,并使用debug模块输出。
--- - hosts: 192.168.100.65 tasks: - shell: echo hello world register: say_hi - debug: var=say_hi
debug输出的结果如下:
TASK [debug] *********************************************
ok: [192.168.100.65] => {
"say_hi": {
"changed": true,
"cmd": "echo hello world",
"delta": "0:00:00.002086",
"end": "2017-09-20 21:03:40.484507",
"rc": 0,
"start": "2017-09-20 21:03:40.482421",
"stderr": "",
"stderr_lines": [],
"stdout": "hello world",
"stdout_lines": [
"hello world"
]
}
}
可以看出,结果是一段json格式的数据,最顶端的key为say_hi,其内是一大段的字典(即使用大括号包围的),其中的stdout_lines还包含了一个json数组,也就是所谓的yaml列表项(即使用中括号包围的)。
1.2.1 引用json字典数据的方式
如果想要输出json数据的某一字典项,则应该使用”key.dict”或”key[‘dict’]”的方式引用。例如最常见的stdout项”hello world”是想要输出的项,以下两种方式都能引用该字典变量。
--- - hosts: 192.168.100.65 tasks: - shell: echo hello world register: say_hi - debug: var=say_hi.stdout - debug: var=sya_hi['stdout']
ansible-playbook的部分输出结果如下:
TASK [debug] ************************************************
ok: [192.168.100.65] => {
"say_hi.stdout": "hello world"
}
TASK [debug] ************************************************
ok: [192.168.100.65] => {
"say_hi['stdout']": "hello world"
}
“key.dict”或”key[‘dict’]”的方式都能引用,但在dict字符串本身就包含”.”的时候,应该使用中括号的方式引用。例如:
anykey[‘192.168.100.65’]
1.2.2 引用json数组数据的方式
如果想要输出json数据中的某一数组项(列表项),则应该使用”key[N]”的方式引用数组中的第N项,其中N是数组的index,从0开始计算。如果不使用index,则输出的是整个数组列表。
例如想要输出上面的stdout_lines中的”hello world”,它是数组stdout_lines中第一项所以使用stdout_lines[0]来引用,再加上stdout_lines上面的say_hi,于是引用方式如下:
--- - hosts: 192.168.100.65 tasks: - shell: echo hello world register: say_hi - debug: var=say_hi.stdout_lines[0]
由于stdout_lines中仅有一项,所以即使不使用index的方式即say_hi.stdout_lines也能得到期望的结果。输出结果如下:
TASK [debug] *************************************************
ok: [192.168.100.65] => {
"say_hi.stdout_lines[0]": "hello world"
}
再看下面一段json数据。
"ipv6": [
{
"address": "fe80::20c:29ff:fe26:1498",
"prefix": "64",
"scope": "link"
}
]
其中key=ipv6,其内有且仅有是一个列表项,但该列表内包含了数个字典项。要引用列表内的字典,例如上面的address项。应该如下引用:
ipv6[0].address
1.2.3 引用facts数据
既然已经了解了json数据中的字典和列表列表项的引用方式,显然facts中的一大堆数据就能引用并派上用场了。例如以下是一段facts数据。
shell> ansible localhost -m setup -a "filter=*eth*"
localhost | SUCCESS => {
"ansible_facts": {
"ansible_eth0": {
"active": true,
"device": "eth0",
"features": {
"busy_poll": "off [fixed]",
"fcoe_mtu": "off [fixed]",
"generic_receive_offload": "on",
.........................
},
"ipv4": {
"address": "192.168.100.62",
"broadcast": "192.168.100.255",
"netmask": "255.255.255.0",
"network": "192.168.100.0"
},
"macaddress": "00:0c:29:d9:0b:71",
"module": "e1000",
............................
}
},
"changed": false
}
显然,facts数据的顶级key为ansible_facts,在引用时应该将其包含在变量表达式中。但自动收集的facts比较特殊,它以ansible_facts作为key,ansible每次收集后会自动将其注册为变量,所以facts中的数据都可以直接通过变量引用,甚至连顶级key ansible_facts都要省略。
例如引用上面的ipv4的地址address项。
ansible_eth0.ipv4.address
而不能写成:
ansible_facts.ansible_eth0.ipv4.address
但其他任意时候,都应该带上所有的key。
1.3 设置本地facts
在ansible收集facts时,还会自动收集/etc/ansible/facts.d/*.fact文件内的数据到facts中,且以ansible_local做为key。目前fact支持两种类型的文件:ini和json。当然,如果fact文件的json或ini格式写错了导致无法解析,那么肯定也无法收集。
例如,在/etc/ansible/facts.d目录下存在一个my.fact的文件,其内数据如下:
shell> cat /etc/ansible/facts.d/my.fact
{
"family": {
"father": {
"name": "Zhangsan",
"age": "39"
},
"mother": {
"name": "Lisi",
"age": "35"
}
}
}
ansible收集facts后的本地facts数据如下:
shell> ansible localhost -m setup -a "filter=ansible_local"
localhost | SUCCESS => {
"ansible_facts": {
"ansible_local": {
"my": {
"family": {
"father": {
"age": "39",
"name": "Zhangsan"
},
"mother": {
"age": "35",
"name": "Lisi"
}
}
}
}
},
"changed": false
}
可见,如果想要引用本地文件中的某个key,除了带上ansible_local外,还必须得带上fact文件的文件名。例如,引用father的name。
ansible_local.my.family.father.name
1.4 输出和引用变量
上文已经展示了一种变量的引用方式:使用debug的var参数。debug的另一个参数msg也能输出变量,且msg可以输出自定义信息,而var参数只能输出变量。
另外,msg和var引用参数的方式有所不同。例如:
---
- hosts: 192.168.100.65
tasks:
- debug: 'msg="ipv4 address: {{ansible_eth0.ipv4.address}}"'
- debug: var=ansible_eth0.ipv4.address
msg引用变量需要加上双大括号包围,既然加了大括号,为了防止被解析为内联字典,还得加引号包围。这里使用了两段引号,因为其内还包括了一个”: “,加引号可以防止它被解析为”key: “的格式。而var参数引用变量则直接指定变量名。
这就像bash中引用变量的方式是一样的,有些时候需要加上$,有些时候不能加$。也就是说,当引用的是变量的值,就需要加双大括号,就像加$一样,而引用变量本身,则不能加双大括号。其实双大括号是jinja2中的分隔符。
执行的部分结果如下:
TASK [debug] *****************************************************
ok: [192.168.100.65] => {
"msg": "ipv4 address: 192.168.100.65"
}
TASK [debug] *****************************************************
ok: [192.168.100.65] => {
"ansible_eth0.ipv4.address": "192.168.100.65"
}
几乎所有地方都可以引用变量,例如循环、when语句、信息输出语句、template文件等等。只不过有些地方不能使用双大括号,有些地方需要使用。
1.5 注册和定义变量的各种方式
ansible中定义变量的方式有很多种,大致有:(1)将模块的执行结果注册为变量;(2)直接定义字典类型的变量;(3)role中文件内定义变量;(4)命令行传递变量;(5)借助with_items迭代将多个task的结果赋值给一个变量;(6)inventory中的主机或主机组变量;(7)内置变量。
1.5.1 register注册变量
使用register选项,可以将当前task的输出结果赋值给一个变量。例如,下面的示例中将echo的结果”haha”赋值给say_hi变量。注意,模块的输出结果是json格式的,所以,引用变量时要指定引用的对象。
--- - hosts: localhost tasks: - shell: echo haha register: say_hi - debug: var=say_hi.stdout
1.5.2 set_fact定义变量
set_fact和register的功能很相似,也是将值赋值给变量。它更像shell中变量的赋值方式,可以将某个变量的值赋值给另一个变量,也可以将字符串赋值给变量。
例如:
---
- hosts: 192.168.100.65
tasks:
- shell: echo haha
register: say_hi
- set_fact: var1="{{say_hi.stdout}}"
- set_fact: var2="your name is"
- debug: msg="{{var2}} {{var1}}"
1.5.3 vars定义变量
可以在play或task层次使用vars定义字典型变量。如果同名,则task层次的变量覆盖play层次的变量。
例如:
---
- hosts: localhost
vars:
var1: value1
var2: value2
tasks:
- debug: msg="{{var1}} {{var2}}"
vars:
var2: value2.2
输出结果为:
TASK [debug] ********************************************
ok: [localhost] => {
"msg": "value1 value2.2"
}
1.5.4 vars_files定义变量
和vars一样,只不过它是将变量以字典格式定义在独立的文件中,且vars_files不能定义在task层次,只能定义在play层次。
---
- hosts: localhost
vars_files:
- /tmp/var_file1.yml
- var_file2.yml
tasks:
- debug: msg="{{var1}} {{var2}}"
上面var_file2.yml使用的是相对路径,基于playbook所在的路径。例如该playbook为/tmp/x.yml,则var_file2.yml也应该在/tmp下。当然,完全可以使用绝对路径。
1.5.5 roles中的变量
由于role是整合playbook的,它有默认的文件组织结构。其中有一个目录vars,其内的main.yml用于定义变量。还有defaults目录内的main.yml则是定义role默认变量的,默认变量的优先级最低。
shell> tree /yaml /yaml ├── roles │ └── nginx │ ├── defaults │ └── main.yml │ ├── files │ ├── handlers │ ├── meta │ ├── tasks │ ├── templates │ └── vars │ └── main.yml └── site.yml
main.yml中变量定义方式也是字典格式,例如:
--- mysql_port: 3306
1.5.6 命令行传递变量
ansible和ansible-playbook命令的”-e”选项都可以传递变量,传递的方式有两种:-e key=value和-e @var_file。注意,当key=value方式传递变量时,如果变量中包含特殊字符,必须防止其被shell解析。
例如:
ansible localhost -m shell -a "echo {{say_hi}}" -e 'say_hi="hello world"'
ansible localhost -m shell -a "echo {{say_hi}}" -e @/tmp/var_file1.yml
其中/tmp/var_file1.yml中的内容如下:
--- say_hi: hello world
1.5.7 借助with_items叠加变量
ansible中可以借助with_items实现列表迭代的功能,作用于变量注册的行为上,就可以实现将多个结果赋值给同一个变量。
例如下面的playbook中,给出了3个item列表,并在shell模块中通过固定变量”{{item}}”分别迭代,第一次迭代的是haha,第二次迭代的是heihei,第三次迭代的是hehe,也就实现了3次循环。最后,将结果注册为变量hi_var。
---
- hosts: localhost
remote_user: root
tasks:
- name: test #
shell: echo "{{item}}"
with_items:
- haha
- heihei
- hehe
register: hi_var
- debug: var=hi_var.results[0].stdout
- debug: var=hi_var.results[1].stdout
- debug: var=hi_var.results[2].stdout
每次迭代的过程中,调用item的模块都会将结果保存在一个key为results的数组中。因此,引用迭代后注册的变量时,需要在变量名中加上results,并指定数组名。例如上面的hi_var.results[N].stdout。
还可以使用for循环遍历列表。例如:
- debug: msg="{% for i in hi_var.results %} {{i.stdout}} {% endfor %}"
其实,看一下hi_var的输出就很容易理解了。以下是hi_var的第一个列表的输出。
"hi_var": {
"changed": true,
"msg": "All items completed",
"results": [
{
"_ansible_item_result": true,
"_ansible_no_log": false,
"_ansible_parsed": true,
"changed": true,
"cmd": "echo \"haha\"",
"delta": "0:00:00.001942",
"end": "2017-09-21 04:45:57.032946",
"invocation": {
"module_args": {
"_raw_params": "echo \"haha\"",
"_uses_shell": true,
"chdir": null,
"creates": null,
"executable": null,
"removes": null,
"warn": true
}
},
"item": "haha",
"rc": 0,
"start": "2017-09-21 04:45:57.031004",
"stderr": "",
"stderr_lines": [],
"stdout": "haha",
"stdout_lines": [
"haha"
]
}
1.5.8 inventory中主机变量和主机组变量
在inventory文件中可以为主机和主机组定义变量,不仅包括内置变量赋值,还包括自定义变量赋值。例如以下inventory文件。
192.168.100.65 ansible_ssh_port=22 var1=1 [centos7] 192.168.100.63 192.168.100.64 192.168.100.65 var1=2 [centos7:vars] var1=2.2 var2=3 [all:vars] var2=4
其中ansible_ssh_port是主机内置变量,为其赋值22,这类变量是设置类变量,不能被引用。此外还在多处为主机192.168.100.65进行了赋值。其中[centos7:vars]和[all:vars]表示为主机组赋值,前者是为centos7这个组赋值,后者是为所有组赋值。
以下是执行语句:
shell> ansible 192.168.100.65 -i /tmp/hosts -m shell -a 'echo "{{var1}} {{var2}}"'
192.168.100.65 | SUCCESS | rc=0 >>
2 3
从结果可知,主机变量优先级高于主机组变量,给定的主机组变量优先级高于all特殊组。
除了在inventory文件中定义主机、主机组变量,还可以将其定义在host_vars和group_vars目录下的独立的文件中,但要求这些host_vars或group_vars这两个目录和inventory文件或playbook文件在同一个目录下,且变量的文件以对应的主机名或主机组名命名。
例如,inventory文件路径为/etc/ansible/hosts,playbook文件路径为/tmp/x.yml,则主机192.168.100.65和主机组centos7的变量文件路径可以为以下几种:
- /etc/ansible/host_vars/192.168.100.65
- /etc/ansible/group_vars/centos7
- /tmp/host_vars/192.168.100.65
- /tmp/group_vars/centos7
以下为几个host_vars和group_vars目录下的文件内容。
shell> cat /etc/ansible/{host_vars/192.168.100.65,group_vars/centos7} \
/tmp/{host_vars/192.168.100.65,group_vars/centos7}
var1: 1
var2: 2
var3: 3
var4: 4
以下为/tmp/x.yml的内容。
---
- hosts: 192.168.100.65
tasks:
- debug: msg='{{var1}} {{var2}} {{var3}} {{var4}}'
执行结果如下:
TASK [debug] **********************************************
ok: [192.168.100.65] => {
"msg": "1 2 3 4"
}
1.5.9 内置变量
ansible除了inventory中内置的一堆不可被引用的设置类变量,还有几个全局都可以引用的内置变量,主要有以下几个:
inventory_hostname、inventory_hostname_short、groups、group_names、hostvars、play_hosts、inventory_dir和ansible_version。
1.inventory_hostname和inventory_hostname_short
分表代表的是inventory中被控节点的主机名和主机名的第一部分,如果定义的是主机别名,则变量的值也是别名。
例如inventory中centos7主机组定义为如下:
[centos7] 192.168.100.63 host1 ansible_ssh_host=192.168.100.64 www.host2.com ansible_ssh_host=192.168.100.65
分别输出它们的inventory_hostname和inventory_hostname_short。
shell> ansible centos7 -m debug -a 'msg="{{inventory_hostname}} & {{inventory_hostname_short}}"'
192.168.100.63 | SUCCESS => {
"msg": "192.168.100.63 & 192"
}
host1 | SUCCESS => {
"msg": "host1 & host1"
}
www.host2.com | SUCCESS => {
"msg": "www.host2.com & www"
}
2.groups和group_names
group_names返回的是主机所属主机组,如果该主机在多个组中,则返回多个组,如果它不在组中,则返回ungrouped这个特殊组。
例如,某个inventory文件如下:
192.168.100.60 192.168.100.63 192.168.100.64 192.168.100.65 [centos6] 192.168.100.60 [centos7] 192.168.100.63 host1 ansible_ssh_host=192.168.100.64 www.host2.com ansible_ssh_host=192.168.100.65 [centos:children] centos6 centos7
其中100.60定义在centos6和centos中,所以返回这两个组。同理100.63返回centos7和centos。100.64和100.65则返回ungrouped,虽然它们在centos7中都定义了别名,但至少将100.64和100.65作为主机名时,它们是不在任何主机中的。另一方面,host1和www.host2.com这两个别名主机都返回centos7和centos两个组。
groups变量则是返回其所在inventory文件中所有组和其内主机名。注意,该变量对每个控制节点都返回一次,所以返回的内容可能非常多。例如,上面的inventory中,如果指定被控节点为centos7,则会重复返回3次(因为有3台被控主机)该inventory文件。其中的第三台主机www.host2.com的返回结果为:
www.host2.com | SUCCESS => {
"msg": {
"all": [
"192.168.100.60",
"192.168.100.63",
"192.168.100.64",
"192.168.100.65",
"host1",
"www.host2.com"
],
"centos": [
"192.168.100.60",
"192.168.100.63",
"host1",
"www.host2.com"
],
"centos6": [
"192.168.100.60"
],
"centos7": [
"192.168.100.63",
"host1",
"www.host2.com"
],
"ungrouped": [
"192.168.100.60",
"192.168.100.63",
"192.168.100.64",
"192.168.100.65"
]
}
}
3.hostvars
该变量用于引用其他主机上收集的facts中的数据,或者引用其他主机的主机变量、主机组变量。其key为主机名或主机组名。
举个例子,假如使用ansible部署一台php服务器host1,且配置文件内需要指向另一台数据库服务器host2的ip地址ip2,可以直接在配置文件中指定ip2,但也可以在模板配置文件中直接引用host2收集的facts数据中的ansible_eth0.ipv4.address变量。
例如,centos7主机组中包含了192.168.100.[63:65]共3台主机。playbook内容如下:
---
- hosts: centos7
tasks:
- debug: msg="{{hostvars['192.168.100.63'].ansible_eth0.ipv4.address}}"
执行结果如下:
TASK [debug] *********************************************************
ok: [192.168.100.63] => {
"msg": "192.168.100.63"
}
ok: [192.168.100.64] => {
"msg": "192.168.100.63"
}
ok: [192.168.100.65] => {
"msg": "192.168.100.63"
}
但注意,在引用其他主机facts中数据时,要求被引用主机进行了facts收集动作,或者有facts缓存。否则都没收集,当然无法引用其facts数据。也就是说,当被引用主机没有facts缓存时,ansible的控制节点中必须同时包含引用主机和被引用主机。
除了引用其他主机的facts数据,还可以引用其他主机的主机变量和主机组变量,且不要求被引用主机有facts数据,因为主机变量和主机组变量是在ansible执行任务前加载的。
例如,inventory中格式如下:
192.168.100.59 [centos7] 192.168.100.63 var63=63 192.168.100.64 192.168.100.65 [centos7:vars] var64=64
playbook内容如下:
---
- hosts: 192.168.100.59
tasks:
- debug: msg="{{hostvars['192.168.100.63'].var63}} & {{hostvars['192.168.100.65'].var64}}"
执行结果如下:
TASK [debug] ***************************************
ok: [192.168.100.59] => {
"msg": "63 & 64"
}
4.play_hosts和inventory_dir
play_hosts代表的是当前play所涉及inventory内的所有主机名列表。
例如,inventory内容为:
192.168.100.59 [centos6] 192.168.100.62 192.168.100.63 [centos7] 192.168.100.64 192.168.100.65
那么,该inventory内的任意一或多台主机作为ansible或ansible-playbook的被控节点时,都会返回整个inventory内的所有主机名称。
inventory_dir是所使用inventory所在的目录。
5.ansible_version
代表的是ansible软件的版本号。变量返回的内容如下:
{
"full": "2.3.1.0",
"major": 2,
"minor": 3,
"revision": 1,
"string": "2.3.1.0"
}
转自:博客园骏马金龙https://www.cnblogs.com/f-ck-need-u/p/7571974.html





评论前必须登录!
注册