
Scrapy基础使用方法总结 【四】——xpath
接 Scrapy基础使用方法总结 【三】——xpath xpath常用语法 parent::,通过子标签获取父标签,如//p[@id=”u...
接 Scrapy基础使用方法总结 【三】——xpath xpath常用语法 parent::,通过子标签获取父标签,如//p[@id=”u...

一、简介 xpath,全程为xml path language。 两个可视化测试xpath和css语法的网站: https://try.jsoup.org/ h...
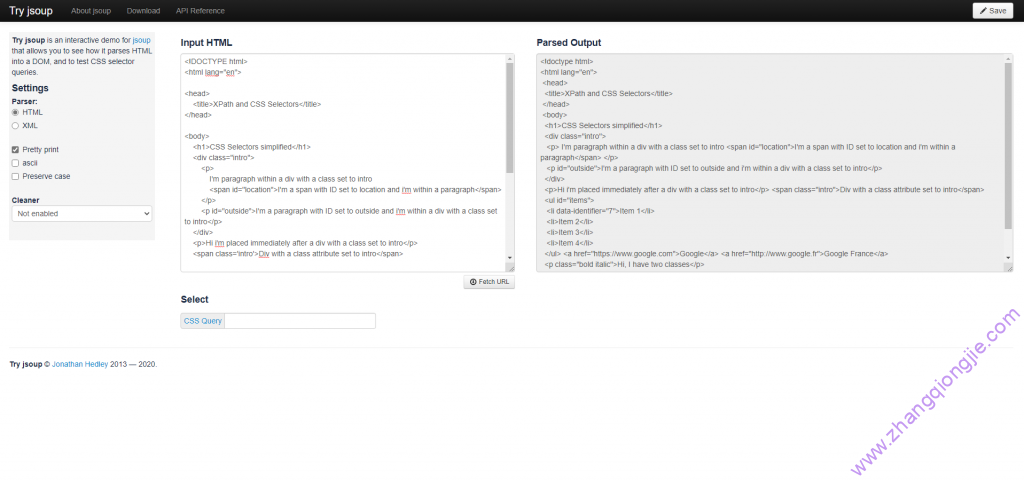
一、简述 通过使用css来对web网站进行筛选,过滤出我们想要爬取的内容,这里是一个示例代码html文件,为下面演示使用(可点击 这里 这里code 免费下载)...

1. 下载anaconda程序包 点击这里开始下载 2.打开anaconda UI界面 可以看到默认base环境,显示本机已安装的一些程序,如下截图 3.安装s...

